A set of selected examples are shown below. More tasks are shown in the [Online Demo].
Generating target images given visual prompts.
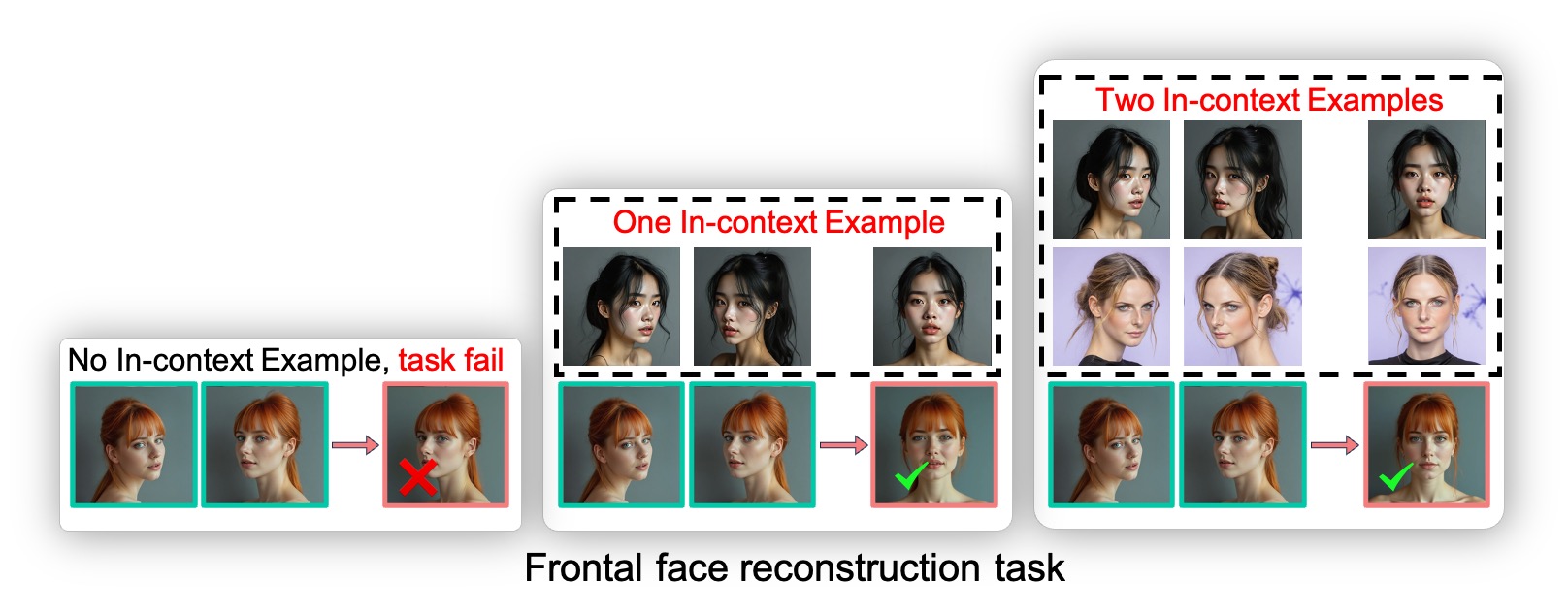
Generalization to Unseen Tasks via In-Context Learning
The model, if relying solely on language instructions, struggles to generalize to different tasks.
Instead, in-context learning allows the model to understand and perform tasks from a few demonstrations.
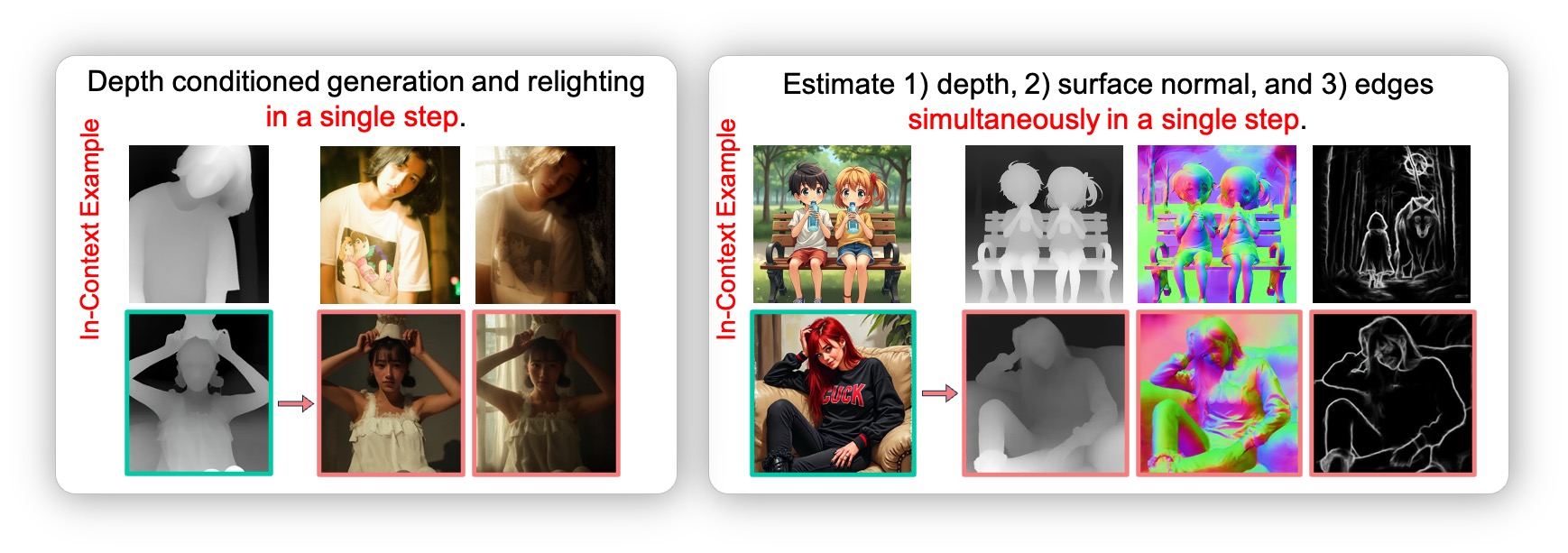
Unseen Tasks:Unifying Multiple Tasks into One Step
Interestingly,
we find that our method can unify multiple tasks into one step and
generate not only the target image but also the intermediate results.
Unseen Tasks:Reverse Generation
Our method supports reverse generation, i.e., reverse-engineering a set of conditions from a target.
Abstract
Recent progress in diffusion models significantly advances various image generation tasks.
However, the current mainstream approach remains focused on building task-specific models,
which have limited efficiency when supporting a wide range of different needs.
While universal models attempt to address this limitation,
they face critical challenges, including generalizable task instruction,
appropriate task distributions, and unified architectural design.
To tackle these challenges, we propose VisualCloze,
a universal image generation framework,
which supports a wide range of in-domain tasks,
generalization to unseen ones,
unseen unification of multiple tasks,
and reverse generation.
Unlike existing methods that rely on language-based task instruction, leading to task ambiguity and weak generalization,
we integrate visual in-context learning, allowing models to identify tasks from visual demonstrations.
Meanwhile, the inherent sparsity of visual task distributions hampers the learning of transferable knowledge across tasks.
To this end, we introduce Graph200K, a graph-structured dataset that establishes various interrelated tasks,
enhancing task density and transferable knowledge.
Furthermore, we uncover that our unified image generation formulation shared a consistent objective with image infilling,
enabling us to leverage the strong generative priors of pre-trained infilling models without modifying the architectures.
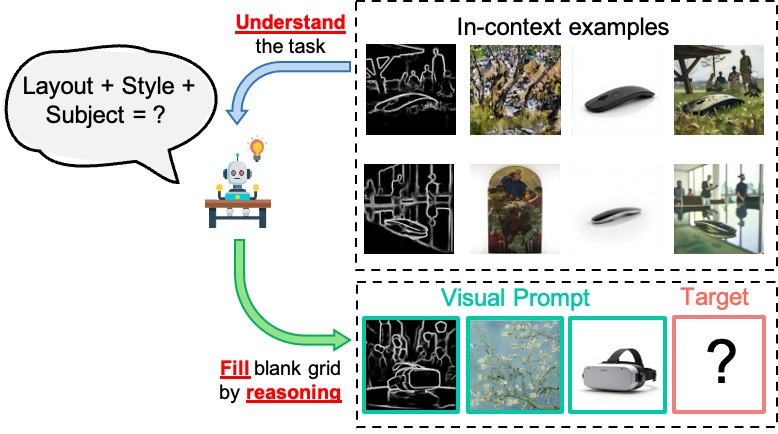
Method
We provide a few in-context examples as visual demonstrations to clarify the desired task.
Specifically, we find that a consistent objective between image in-filling and our in-context learning based universal generative models.
Through concatenating all input and output images into a grid-layout image, the objective of a task is to fill the output area.
To this end, we build VisualCloze upon advanced general-purpose infilling models, i.e., FLUX.1-Fill-dev, without additional modifications in the architecture.
A potential limitation lies in the difficulty of composing a grid image from in-context examples with varying aspect ratios.
To overcome this issue,
we leverage the 3D-RoPE in FLUX.1-Fill-dev to perform context concatenation along the temporal dimension,
effectively overcoming this issue without introducing any noticeable performance degradation.
Dataset
In natural language processing, tasks overlap significantly, facilitating strong cross-task learning ability.
In contrast, visual tasks are inherently distinct, posing challenges for vision models to achieve similar generalization ability via instruction tuning.
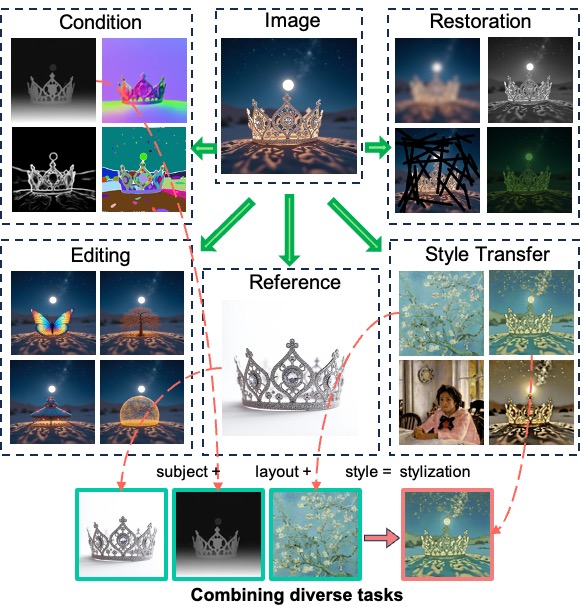
To ease this issue, we introduce a Graph Structured Multi-Task Dataset, named Graph200K.
Graph200K is built upon the Subjects200K dataset.
Each image is annotated for five meta-tasks, including 1) conditional generation, 2) image restoration, 3) image editing, 4) IP preservation, and 5) style transfer.
These tasks can also be combined to form a wide range of complex tasks.
We leave the discussions about data construction in our paper.
BibTex
@InProceedings{Li_2025_ICCV,
author = {Li, Zhong-Yu and Du, Ruoyi and Yan, Juncheng and Zhuo, Le and Li, Zhen and Gao, Peng and Ma, Zhanyu and Cheng, Ming-Ming},
title = {VisualCloze: A Universal Image Generation Framework via Visual In-Context Learning},
booktitle = {Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
month = {October},
year = {2025},
pages = {18969-18979}
}